Elasticsearch provides over 50 different queries. To help you see the forest for the trees, every month, this blog series highlights a different query.
When you send Elasticsearch a search request, it responds with a ranked list of hits. By default, Elasticsearch ranks the hits by score. Elasticsearch calculates this score depending on the query:
- a simple
0or1for “yes/no” queries like range queries. - a distance metric for vector queries.
- a relevance metric for full-text queries, calculated by default using the Okapi BM25 algorithm.
However, there may be times when the default scoring mechanism doesn’t meet your needs. For example, if you’re running an eCommerce store, you might want to list products with higher profit margins above those with lower margins. In such cases, Elasticsearch provides several ways to fully control the scoring. One of those ways is the script score query.
The script score query
The script score query lets you use a custom script to calculate a score for all documents returned by another query. Written in Elasticsearch’s script language, Painless, this script enables you to calculate any number for each document and use that number as its score.
The structure of a script score query request is:
GET /_search
{
"query": {
"script_score": {
"query": {
...
},
"script": {
...
}
}
}
}
- In the
queryclause, you specify the query used to retrieve documents. - In the
scriptclause, you provide the Painless script that calculates the scores.
In the script, you can use the following:
_score, a variable containing a document’s original score.- Several predefined Painless functions.
- Values from fields in the documents, preferably using doc values notation.
An example
Let’s take a look at a trivial example: assigning a random score to all documents that match a query. The following request searches for all documents in the books dataset whose title contains the phrase "war and peace" and assigns a random score to each hit:
GET books/_search
{
"query": {
"script_score": {
"query": {
"match_phrase": {
"title": "war and peace"
}
},
"script": {
"source": "randomScore(1000)"
}
}
}
}
In this example, randomScore is a predefined Painless function. It accepts a numerical seed (in this case, 1000) to ensure consistent random numbers across requests (unless a Lucene merge occurs).
Although this example might seem trivial, a bit of randomness can be useful. For instance, the books dataset contains five editions of “War and Peace” that all score equally for a phrase query for "war and peace". Showing them in the same order every time may cause the one edition that ranks highest to get most of the clicks. To address this, you can add a bit of randomness to the BM25 score, resulting in the hits being shuffled. Using a numerical user ID as the seed ensures that a given user is always shown a consistently shuffled result set:
GET books/_search
{
"query": {
"script_score": {
"query": {
"match_phrase": {
"title": "war and peace"
}
},
"script": {
"source": "_score + randomScore(13456)"
}
}
}
}
Here, _score is a variable containing a document’s original score. 123456 is a user ID.
Document values
You can use the values in a document in the score calculation. For instance, if you want to take a book’s average rating into account by boosting the ranking of higher-rated books, you could sum the original score and the value of the average_rating field.
Accessing fields using doc values is fastest. To access the average_rating field, use:
doc['average_rating'].value
This assumes that every document contains that field. If your data isn’t clean, check whether the field has a value first, otherwise Elasticsearch may return an error. This script returns the unmodified score if a document doesn’t have a value for the average_rating field:
doc['average_rating'].size() == 0 ? _score : _score + doc['average_rating'].value
Putting this together as a search request:
GET books/_search
{
"query": {
"script_score": {
"query": {
"match_phrase": {
"title": "war and peace"
}
},
"script": {
"source": "doc['average_rating'].size() == 0 ? _score : _score + doc['average_rating'].value"
}
}
}
}
Distance scoring with decay functions
Decay functions are a powerful set of predefined Painless functions. They enable you to score documents based on their proximity to a numeric point, date, or geographic location. The shape of the function is determined by the type (linear, Gaussian, or exponential) and four parameters: origin, offset, scale, and decay.
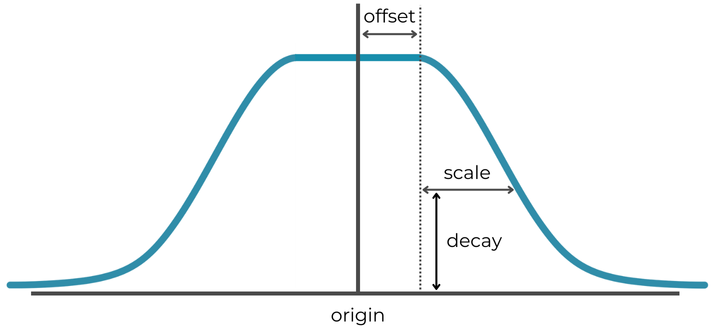
originis the point at which the function returns the maximum value of1.offsetis the range aroundoriginat which the function still returns1.scaleanddecaydetermine the slope of the function. At a distance ofoffset + scale, the function returns the valuedecay.
Suppose you’re looking for a Tolstoy book with around 500 pages. You could:
- Set
originto500. - If anything in the range between 490 and 510 pages should score equally well, you’d set
offsetto10. - If the score should drop to
0.1at 400 or 600 pages, you’d setscaleto90anddecayto0.1.
Using a Gaussian decay function, the search request looks like this:
GET books/_search
{
"query": {
"script_score": {
"query": {
"match": {
"authors": "tolstoy"
}
},
"script": {
"source": "decayNumericGauss(params.origin, params.scale, params.offset, params.decay, doc['num_pages'].value)",
"params": {
"origin": 500,
"offset": 10,
"scale": 90,
"decay": 0.1
}
}
}
}
}
Note that the script uses doc values notation to access the num_pages field: doc['num_pages'].value. This may return an error if a document doesn’t have a value for num_pages. A safer approach is to first check if the document has a value, then access it only if it does:
doc['num_pages'].size() == 0 ? 0 : doc['num_pages'].value
Conclusion
The script score query is a powerful tool that gives you complete control over how scores are calculated. Read more in the official documentation for the script score query.
Published: April 9, 2025 by Abdon